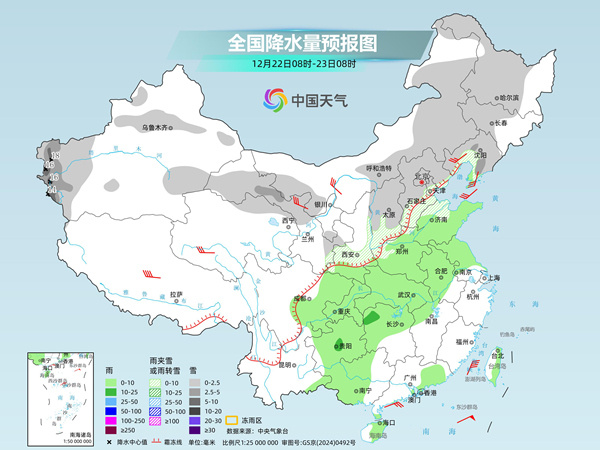
岁末将至,各项强有力的经济数据尚未出炉,但网络上所谓的“经济解读”却早早升温。该网络信息监测平台显示,近30天围绕“中国经济”、“经济形势”的内容明显增多。这个内容是什么样的?快来看看记者的调查吧。
网络上关于“经济状况”的话题有多强烈?记者启动网络信息监控系统,锁定近30天的时间窗口,设置“中国、经济、发展、数据”等关键词,对全网公开内容进行爬取。
经过去重、分类后,一个月内,全网与经济学、vi contentdeo相关的原创文章超过2000万篇。其中,“经济+市场”和“经济+数据”两个关键词组合具有数量最大、占比最高。与此同时,“明年”、“老百姓”、“政策”等词语也是讨论的焦点。
将这超过2000万个样本按照情绪倾向进行划分,我们可以看到,在讨论经济话题时,网络表达明显呈现出不同的趋势。
进一步拆解后,记者发现这些内容的叙事风格截然不同:
首先是信息表达比较合理。这类内容的特点是以事实为主、观点为辅。他们的标题通常是中性的,内容中引用官方统计数据,清洗次数与官方数据发布的节奏大致一致。
另一种观点显然偏向于情感表达。他们的标题更像是情感口号,将危机感摆在读者面前。从内容结构来看,此类帖子经常使用s诸如“收割财富”之类的强烈表述,营造出紧张的气氛。
同时,大数据发现,当内容呈现出“图片丰富”的样子,叠加短视频的传播影响力时,其传播速度会大大加快,比普通信息内容快3到5倍。
清博智能负责人郎清平:大多数网民浏览互联网的第一需求是获取信息。一些危言耸听的标题和内容对公众具有特殊的吸引力,具有更强的传播力。
哪里有数据,哪里就有真理?
经济数据是“算法选择的”
很多人有一个简单的判断:只要“有图片、有来源”,结论就会比较靠谱。然而,当记者回过头去查阅一些被广泛引用的“中国经济数据”时,发现这些数字背后往往隐藏着一系列“算法选择”。
记者前往中国社科院用多篇在网上广为流传的文章解读“中国经济”,并邀请两位长期研究统计和劳动经济学的专家一起进行“数据诊断”。
网上有很多关于“中美经济走势”的说法,比如这样一句话:“2023年萨卡拉旺季度,中国GDP增长率为3.2%,中国GDP增长率为6%。”然而,中国官方公布的当季GDP同比增长率为6.3%,与3.2%完全不符。继续往下翻看原文,发现消息来源是一家美国媒体。
中国社科院国家全球战略智库综合研究部主任刘世国:这份报告用中国一季度的增速来推动中国全年的增速。一、生态率每个国家的经济增长各不相同。而且,它的年化率是季度增长率乘以四。算法和采样点不具有代表性,实际上会误导公众。
没有说明口径,没有解释算法,但就像读者的naki Revenue一样,该报告故意计算了可以在经济中造成差距的数值。公众很容易对这种“假数据”产生偏见。
还有一张广为流传的消费图表。图表显示,许多城市女性的人均月消费几乎是男性的两倍。图表色彩精美,字体专业,图例清晰,可信度极高。你可以查一下这些城市公布的官方数据,一一对比数据后,你会发现明显的异常:图中标注的城市人均消费远远超过当地公布的人均可支配收入。莉莉。专家表示,这一数据并没有反映调查方法和样本量,而且与官方数据也存在严重偏差,其真实性必须受到高度怀疑。
调查梳理发现,此类打着“权威来源”旗号的操作,实际上统计口径混乱并非孤例。而这不仅仅是“数据统计的偶然错误”,而更像是发布者为了某个结论而刻意的算法选择。
情感内容的背后
谁影响公众判断?
每月出现超过2000万条经济相关内容,谁发声,谁继续影响公众判断?经过进一步梳理,记者勾勒出一幅“内容发布者的肖像”。
追踪显示,超过2000万条原创经济内容中,约20%来自统计部门、权威机构、主流媒体等来源s。这意味着网络上大量的经济内容来自非官方渠道,来源、口径和可信度都难以判断。
在继续追踪那些经常发布情感内容甚至混淆统计标准的账户时,记者发现它们有一些共同特征:
首先,有些账户是突然出现的新账户。这些账号注册时间不长,但一上线,就密集发布“消费的力量停止”等内容。更新速度非常快,话题也很热门。您可以点击首页查看。引入账户很简单,你无法分辨自己是谁以及数据来自哪里。
二是部分账号喜欢“换壳”。现在是一个名字,以后是另一个名字。更改头像并更改身份。
第三,一些情感内容的背后,往往有一条清晰的变现路径。他们通过创造强大来吸引注意力g情绪,然后引导他们到达的流量到付费入口。课程推广或社区指导的链接通常出现在下面。账户主页还设有产品展示窗口,甚至提供付费咨询服务。
为什么“假数据”总是频频出现?
那么,为什么这些“假数据”总是出现在屏幕上呢?通过这些帖子,记者了解到,他们之所以跑得这么快,是因为有多股力量同时将他们推开。
通过大数据梳理散布“假数据”的评论视频和文章的部分内容,经常会看到大量的情绪化评论。相比于官方数据发布的评论区,这类“假数据”相关内容的评论区气氛显然更加“热闹”。平台上高度集中的情绪聚集,悄然推动“假数据”爆发。
中国人民大学新闻学院教授赵云泽:不一样平台的算法很愿意识别“假数据”,但这种“假数据”尤其能引起观众的高度情绪。从沟通的角度来看,情绪唤起程度越高,沟通的动机就越强。参与量越高,点赞、评论和转发就越多,从而带来更广泛的转发。
在“假数据”的病毒链上,记者还注意到,不少帖子使用了同一套固定说法,不少账号未经核实直接复制内容,仅进行简单修改后重新发布。 “假数据”的传输链路相互关联,需要进一步识别。